Topic modeling and Magic: The Gathering (Part 2)
In the previous blog post, I introduced how it is possible to use topic modeling to find MTG archetypes with Latent Dirichlet allocation (LDA). The code to do so is available on my GitHub. To visualise the 74 archetypes found, click here. Let me now guide you through the notebook and discuss the results.
Gathering and processing the data
The data analyzed in this post consists of 3718 Legacy decklists registered in 2020 on mtgtop8. To obtain these decklists, I scrapped the content of mtgtop8; see the spider_mtg repo for more details. Also, if you are interested in more Legacy data, I have done the same for other years.
The decklists are stored in a single file, one decklist per line. We have 75 cards in a deck with 60 cards mainboard and 15 cards sideboard:
"3 Bayou 1 Dryad Arbor 2 Marsh Flats 3 Misty Rainforest 3 Polluted Delta 1 Snow-Covered Swamp 3 Underground Sea 4 Verdant Catacombs 4 Bloodghast 4 Gravecrawler 4 Hedron Crab 4 Hogaak, Arisen Necropolis 2 Putrid Imp 4 Stitcher\\'s Supplier 4 Vengevine 4 Cabal Therapy 2 Careful Study 4 Altar of Dementia 4 Bridge from Below 3 Chain of Vapor 4 Force of Vigor 4 Leyline of the Void 1 Oko, Thief of Crowns 3 Thoughtseize "
Our document here is a decklist such as the one above. The corpus, a collection of documents, consists of all the decklists. For the vocabulary, the set of all words used in the corpus, we want to associate each card name in it with a unique integer ID. We do this using gensim.corpora.Dictionary. Following the core concepts of gensim, we take an extra step by constructing a dictionary without loading all the decklists into memory:
dictionary = gensim.corpora.Dictionary([x.strip() for x in re.split(r"[\d]+", line.replace("\"", ""))] for line in open('single_legacy_2020.txt'))
once_ids = [tokenid for tokenid, docfreq in iteritems(dictionary.dfs) if docfreq == 1]
dictionary.filter_tokens(once_ids) # remove cards that appear only once
dictionary.compactify() # remove gaps in id sequence after words that were removed
Likewise for the corpus, we want it to be memory friendly. We define a class MyCorpus:
class MyCorpus(object):
def __iter__(self):
for line in open('single_legacy_2020.txt'):
decklist = line.replace("\"", "") # remove start and end tokens
decklist = re.split(r"([\d]+)", decklist) # split by numbers and card names
decklist = [x.strip() for x in decklist] # remove whitespace
decklist = list(filter(None, decklist)) # remove empty words
cleaned_decklist = []
for i in range(int(len(list(decklist))/2)):
for j in range(int(len(list(decklist[i*2])))):
cleaned_decklist.append(decklist[i*2+1])
yield dictionary.doc2bow(cleaned_decklist)
corpus_memory_friendly = MyCorpus()
In the __iter__ function, we retrieve and clean a list of tokens (card names) in each decklist. With the line yield dictionary.doc2bow(cleaned_decklist) we convert a list of tokenized card names via a dictionary to their ids and yield the resulting bag of words (bow) corpus. To simplify, here we are counting how many times a card name, via its id, appears in a decklist. If we were to add a __print__ function for our MyCorpus object, we would see something like this for one decklist:
[(1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]
The first tuple tells you that the card with the ID 1 has been counted one time in the document. Note that for all these tuples, the second entry is always 1. It is explained by how we created the cleaned list of tokenized card names in the snippet above.
LDA model
Now that we have a corpus, we can proceed to transform it with the gensim LDA model:
def compute_models_coherence(dictionary, corpus_memory_friendly, model, limit, start=2, step=3):
"""
Return topic modeling models and u_mass coherence values for various number of topics.
For more info about coherence, see:
- https://radimrehurek.com/gensim/models/coherencemodel.html
- https://towardsdatascience.com/evaluate-topic-model-in-python-latent-dirichlet-allocation-lda-7d57484bb5d0
Parameters:
----------
dictionary : Gensim dictionary
corpus : Gensim corpus
model : the topic modeling model (lda or nmf)
start: Starting number of topics
limit : Max number of topics
step: increment
Returns:
-------
model_list : List of LDA or NMF topic models
coherence_values : u_mass Coherence values corresponding to the LDA or NMF model
with respective number of topics
"""
coherence_values = []
model_list = []
# We set iterations and passes to the same number
iterations = 50
# See https://groups.google.com/g/gensim/c/z0wG3cojywM to read about the difference between passes and iterations
np.random.seed(1) # For reproductivity
unique_cards = len(dictionary.keys())
if model == 'nmf':
for archetypes in range(start, limit, step):
model= Nmf(corpus=corpus_memory_friendly, num_topics=archetypes,id2word=dictionary,chunksize=2000,
passes=iterations,kappa=.1,minimum_probability=0.01,w_max_iter=300,
w_stop_condition=0.0001,h_max_iter=100,
h_stop_condition=0.001,eval_every=10,
normalize=True,random_state=np.random.seed(1))
model_list.append(model)
coherencemodel = CoherenceModel(model=model, corpus=corpus_memory_friendly,
dictionary=dictionary, coherence='u_mass')
coherence_values.append(coherencemodel.get_coherence())
if model == 'lda':
for archetypes in range(start, limit, step):
alpha_prior = [1.0 / archetypes] * archetypes
beta_prior = [1.0 / archetypes] * unique_cards
model=gensim.models.ldamodel.LdaModel(corpus=corpus_memory_friendly, id2word=dictionary,
num_topics=archetypes, passes=iterations,
alpha = alpha_prior, eta = beta_prior)
model_list.append(model)
coherencemodel = CoherenceModel(model=model, corpus=corpus_memory_friendly,
dictionary=dictionary, coherence='u_mass')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
model_list_lda, coherence_values_lda = compute_coherence_values(dictionary=dictionary,
corpus_memory_friendly = corpus_memory_friendly,
model='lda', start=2, limit=20, step=6)
As stated in Part 1, LDA is a probabilistic and unsupervised algorithm that assumes that a document (decklist) is a mixture of topics (archetypes). An archetype obtained via LDA can be seen as a probability distribution over card names. What you get in the end is a list of weighted card names for each unnamed archetype that has been found. Moreover, you have to decide how many archetypes to find.
To decide what was the best number of archetypes, I added in the compute_models_coherence function the notion of coherence. The coherence score allows to quantitatively evaluate how good a model is. At least, that’s how I understand it. I won’t go into details (for now) and suggest you read this short article and this paper by Roeder et al.. Please note that here, I am looking at tuning only one hyperparameter: the number of archetypes. If you read through the code snippet above, the alpha_prior and beta_prior are fixed for a given number of archetypes.
Results
The optimal number of archetypes is given by the plot below:
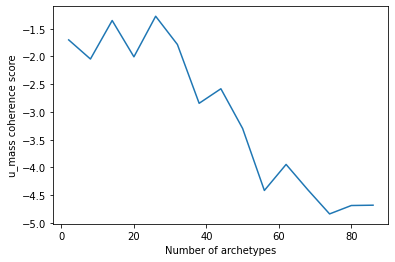
Based on my understanding of the u_mass coherence score, the lower a value is, the better the LDA model is. It seems then that 74 archetypes worked well.
Now, let’s check the top 18 cards of one of the archetype discovered, Archetype 0:
| Archetype 0 |
|---|
| 0.041*Dread Return |
| 0.041*Lotus Petal |
| 0.040*Cabal Therapy |
| 0.039*Narcomoeba |
| 0.039*Bridge from Below |
| 0.038*Golgari Grave-Troll |
| 0.038*Ichorid |
| 0.038*Golgari Thug |
| 0.038*Stinkweed Imp |
| 0.038*Lion's Eye Diamond |
| 0.037*Ashen Rider |
| 0.037*Gemstone Mine |
| 0.036*Cephalid Coliseum |
| 0.035*City of Brass |
| 0.035*Faithless Looting |
| 0.034*Hogaak, Arisen Necropolis |
| 0.032*Leyline of the Void |
| 0.032*Careful Study |
If you want something more visual:

Well, our friend Golgari Grave-Troll, the word dredge and Bridge from Below tell us that Archetype 0 matches Dredge, an archetype so powerful that it creates its own rules ᕕ( ͡° ͜ʖ ͡° )ᕗ.
We can check some other archetypes in the table below. I have indicated in the last row which archetype they match best:
| Archetype 14 | Archetype 73 | Archetype 17 | Archetype 54 |
|---|---|---|---|
| 0.062*Phyrexian Revoker | 0.055*Green Sun's Zenit | 0.034*Goblin Trashmaste | 0.053*Thassa's Oracle |
| 0.043*Karn, Scion of Urza | 0.053*Dryad Arbor | 0.032*Mountain | 0.045*Aether Vial |
| 0.040*Lodestone Golem | 0.038*Collector Ouphe | 0.031*Pyrokinesis | 0.043*Force of Will |
| 0.039*Stonecoil Serpent | 0.037*Scavenging Ooze | 0.031*Goblin Ringleader | 0.039*Cabal Therapy |
| 0.037*Wasteland | 0.036*Savannah | 0.031*Goblin Matron | 0.039*Nomads en-Kor |
| 0.036*Arcbound Ravager | 0.033*Wasteland | 0.031*Cavern of Souls | 0.039*Cephalid Illusionist |
| 0.034*Mishra's Factory | 0.031*Sylvan Library | 0.031*Goblin Cratermaker | 0.037*Narcomoeba |
| 0.034*Chalice of the Void | 0.029*Swords to Plowshares | 0.031*Goblin Chainwhirler | 0.037*Dread Return |
| 0.034*Thorn of Amethyst | 0.028*Knight of the Reliquary | 0.030*Goblin Lackey | 0.036*Shuko |
| 0.033*Walking Ballista | 0.028*Windswept Heath | 0.030*Goblin Warchief | 0.035*Daze |
| 0.033*Ancient Tomb | 0.026*Karakas | 0.028*Gempalm Incinerator | 0.035*Underground Sea |
| 0.033*Umezawa's Jitte | 0.026*Noble Hierarch | 0.027*Aether Vial | 0.034*Polluted Delta |
| 0.033*City of Traitors | 0.025*Knight of Autumn | 0.027*Wasteland | 0.032*Flooded Strand |
| 0.032*Mox Opal | 0.023*Ramunap Excavator | 0.027*Skirk Prospector | 0.030*Stoneforge Mystic |
| 0.031*Karakas | 0.022*Forest | 0.027*Badlands | 0.030*Recruiter of the Guard |
| 0.031*Leyline of the Void | 0.021*Questing Beast | 0.026*Rishadan Port | 0.030*Batterskull |
| 0.031*Sorcerous Spyglass | 0.019*Verdant Catacombs | 0.026*Munitions Expert | 0.029*Ponder |
| 0.029*Steel Overseer | 0.019*Gaddock Teeg | 0.026*Sling-Gang Lieutenant | 0.028*Brainstorm |
| Steel and Taxes | Maverick | Goblins | Cephalid Breakfast |
I am satisfied that among the archetypes discovered classics such as Goblins and Maverick are matched. I was also impressed that the model managed to find something such as Cephalid Breakfast! However, there can be some surprising results such as Archetype 42 for instance:

Archetype 42 matches UB Rogues except for two cards found usually in Goblins: Conspicuous Snoop and Boggart Harbinger. Obviously, it is not too bad since two outliers out of 18 do not prevent identifying existing archetypes. However, it would be interesting to know why it happened.
I do not claim to be an expert of the Legacy format but using my knowledge and mtgdecks.net, I have checked personally 44 archetypes out of 74 and found 36 matches to existing archetypes. The 8 remaining ones seem to be a mix of different existing archetypes.
Visualising the results with pyLDAvis
To make sense of the different archetypes found by our model, we need to go through them individually. With more than 50 topics, it can get tedious. Even more so when trying to see how different archetypes relate to each other. Fortunately, there is a Python library called pyLDAvis that gives a two-dimensional representation of the topics/archetypes found. In the notebook this is achieved via the lines:
pyLDAvis.enable_notebook()
gensim.corpora.MmCorpus.serialize('SerializedCorpus_legacy_2020_74_archetypes.mm'.format(i), corpus_memory_friendly)
SerializedCorpus = gensim.corpora.MmCorpus('SerializedCorpus_legacy_2020_74_archetypes.mm'.format(i))
vis_data = pyLDAvis.gensim.prepare(model_list_lda[-3], SerializedCorpus, dictionary,sort_topics=False)
pyLDAvis.save_html(vis_data, 'LDA_Visualization_legacy_2020_74_archetypes.html'.format(i))
The archetypes are then represented like below:
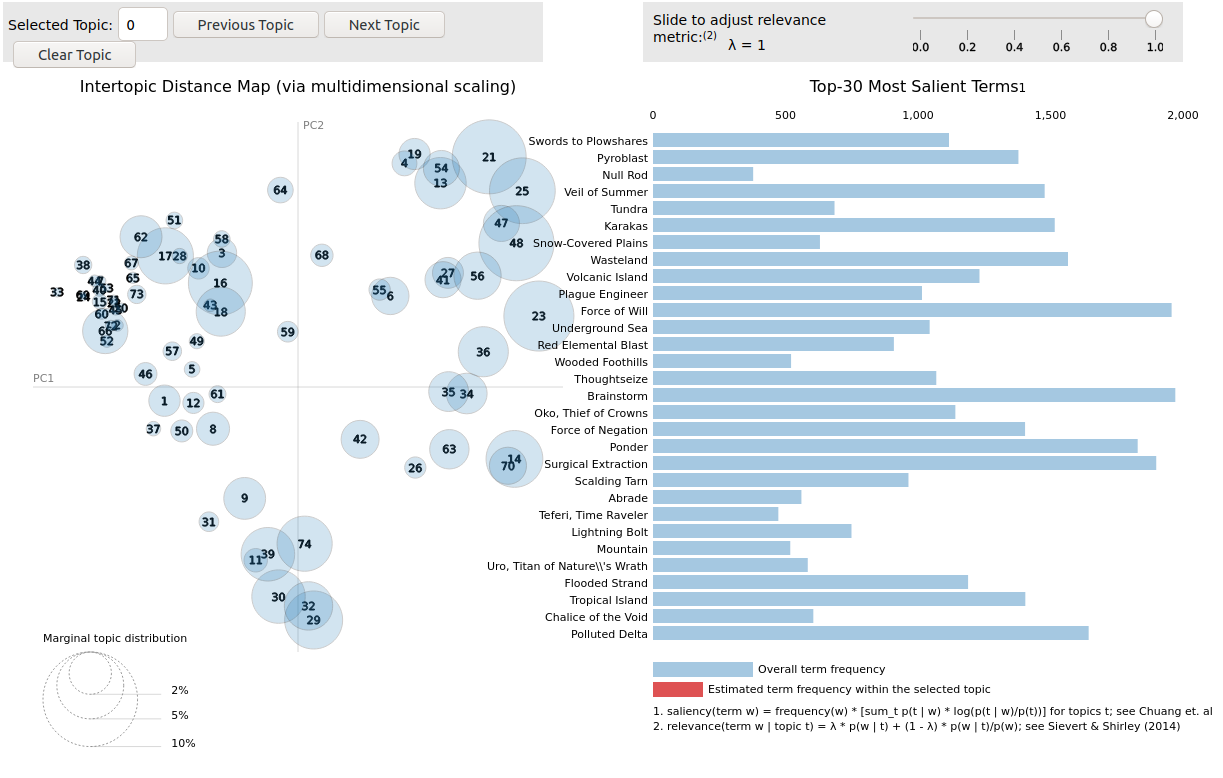
To see it for yourselves, click here and launch interactive exploration of the figure above. Feel free to look at it and also to generate others via the notebook!
For each archetype, represented by a bubble, we get the top 30 most salient card names. The size of a bubble has to do with the percentage of the card names in the corpus. For instance, the archetypes on the right part of the plot (21, 48, or 23) contain cards such as Force of Will, Brainstorm, or Swords to Plowshare. These cards are absolute all-stars in the Legacy formats, being among the most used. Now, if you are curious about the axes, I believe they are not interpretable by themselves: they came out of a multidimensional scaling algorithm.
This representation is trying to maintain information about the archetype’s distances, how closely related they are to each other, as best as it could. It is then possible to see that a lot of archetypes can overlap with each other. Take Archetype 42, the one which matches UB Rogues but contains 2 outliers in Conspicuous Snoop and Boggart Harbinger. Navigating on the plot, you’ll be able to see that it is overlapping with Archetype 18, aka Goblins. These two archetypes share cards such as Cavern of Souls or Thorn of Amethyst. This might a start if you are still obsessed about why two Goblins ended up being part of the UB Rogue archetype.
Conclusion
To end this post, we can confirm that it is possible to find Magic: The Gathering archetypes with Latent Dirichlet Allocation. For a format as complex a Legacy, it is possible to find common (Goblins, Elves) and less common (Steel and Taxes, Cephalid Breakfast) archetypes. It is even possible to start finding variations such as Grixis Delver and Sultai Delver. However, as seen with the pyLDAvis plot, archetypes can share common cards (Force of Will, Brainstorm, Swords to Plowshare) despite very different gameplay. Interpreting LDA model results is not as straightforward as we think. While I am familiar with the subject here, Magic: The Gathering, I can imagine how troublesome this could be when dealing with something more complex like a corpus of tweets.
To do
Things that we could explore:
- finish identifying the archetypes;
- for a given new deck, find the most relevant archetypes among the ones that the model found;
- for two decks, explore how similar they are using the LDA model;
- hyperparameters tuning;
- test other topic modeling algorithms (Non-Negative Matrix Factorization for instance).